索引设计(前缀索引)
索引设计(前缀索引)
当字段类型为字符串(varchar,text,longtext等)时,有时候需要索引很长的字符串,这会让索引变得很大,查询时,浪费大量的磁盘IO, 影响查询效率。
此时可以只将字符串的一部分前缀(因为这一部分前缀就可以进行区分大部分数据了),建立索引,这样可以大大节约索引空间,从而提高索引效率。
语法:create index idx_xxxx on table_name(column(n))
可以这样想,一个表中的一个字段通过前5位就能唯一标识一条数据,那为什么要比较后面的了呢,前缀索引其实就是这个思想。
那我们怎么知道前几位就能区分数据呢,可以根据索引的选择性来决定
索引的选择性
选择性是指不重复的索引值(基数)和数据表的记录总数的比值, 索引选择性越高则查询效率越高, 唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
select count(distinct substring(email,1,5)) / count(*) from tb_user ; --得到前5位数字并且进行去重得到的数量/总数,如果这个值很接近1,就说明可以用前5位 |
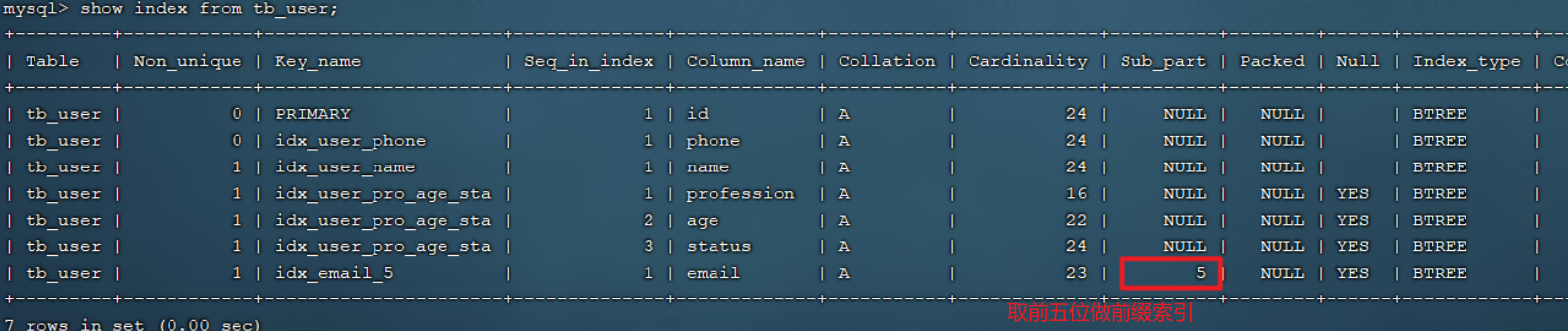
举例: 为tb_user表的email字段,建立长度为5的前缀索引。
create index idx_email_5 on tb_user(email(5));
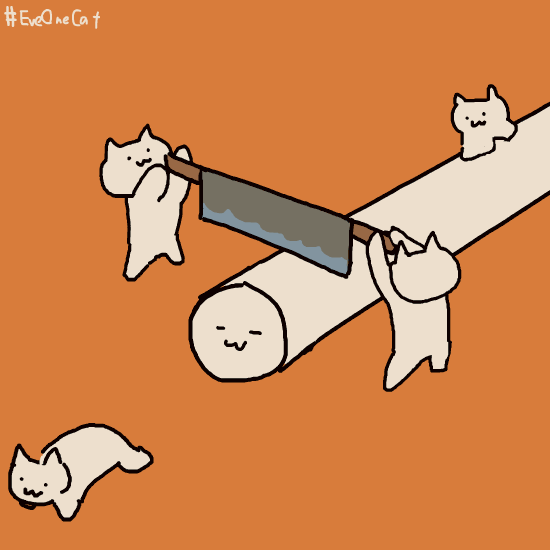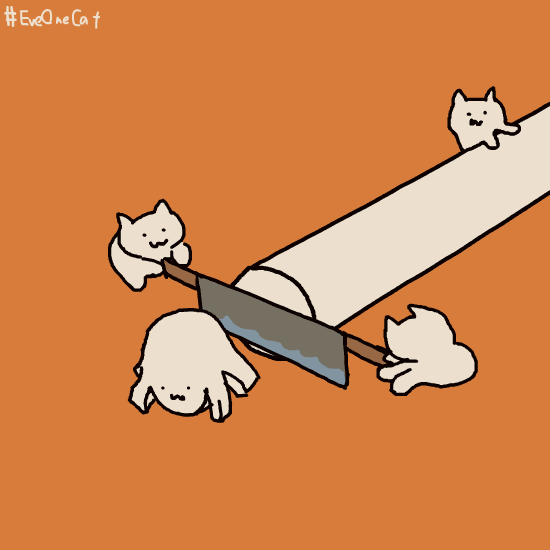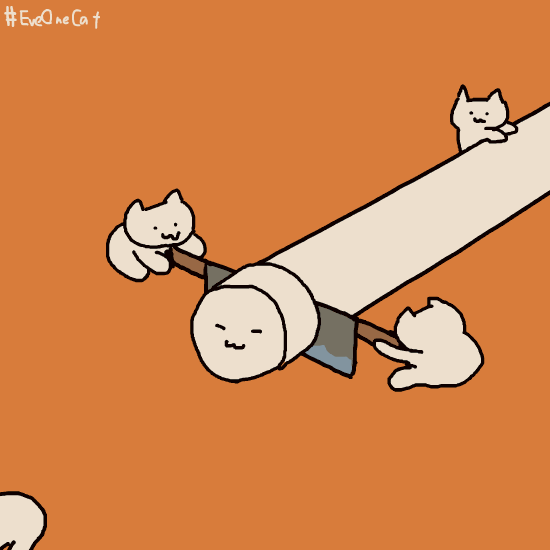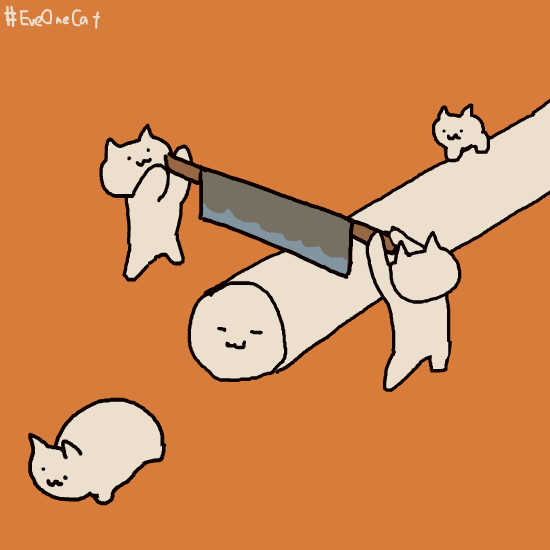
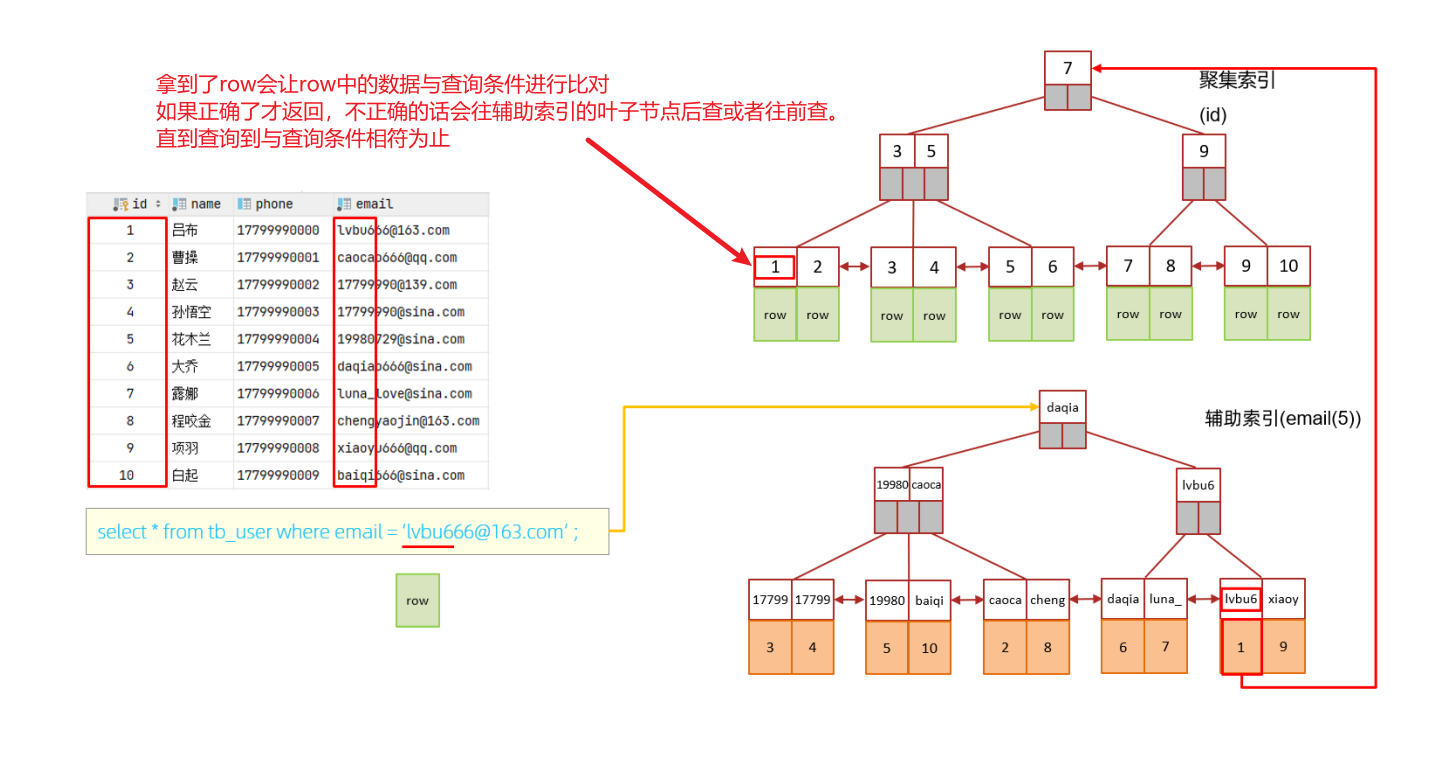
那么前缀索引是怎么进行判断这条唯一数据的呢?下面是一个示意图
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 是小白菜哦!