一文教会你为什么索引的底层数据结构是B+树
一文教会你为什么索引的底层数据结构是B+树
首先我们要知道: B+Tree索引 最常见的索引类型,大部分引擎都支持 B+ 树索引 。
作为存储引擎的老大,InnoDB也采用的是B+树索引(但是提前说一下,他使用的B+树是经过优化的版本,比B+树更厉害,后文会详细介绍)
那么为什么B+树做存储引擎这么NB呢?
首先,我们要知道,存储引擎靠什么nb?答案:一是存储量,二是查询速度
我们可以从查询速度入手,先来看看二叉树
二叉树
二叉树是我们比较熟悉的一种数据结构,二叉树查询速度要比普通的查询(可以理解为一个数组进行查询)快的多。
但是呢,我说几个不好的点,你就会知道为什么不使用二叉树做数据结构了
- 如果数据是顺序插入的,就会形成一个单向的二叉树。比如长这样

- 有没有发现它的层级很深很深,你可能会说,这也不深啊,不就几层,我要存储数据啊,肯定会深一点啊,这样你就错了,因为有更好的数据结构,比如说一个节点里面存储多个值,这样的话节点数少了,层数也少了,当然,这个后面就会说。
所以总结上面两条问题,所以二叉树如果做索引结构,会存在如下的缺点:
- 万一第一个根节点选的不好的话,顺序插入时,会形成一个类链表结构,导致检索速度慢。
- 大数据量情况下,层级较深,检索速度慢 。
你可能会说:这都是检索慢啊,咋优化一下啊?
下面从第一个缺点来想,你说我可能根节点选的不好,那么我想到一种数据结构,是自平衡的二叉树,这不就不会形成一种类链表的结构了嘛。
这就是我要说的第二种数据结构
红黑树
红黑树就长这样:
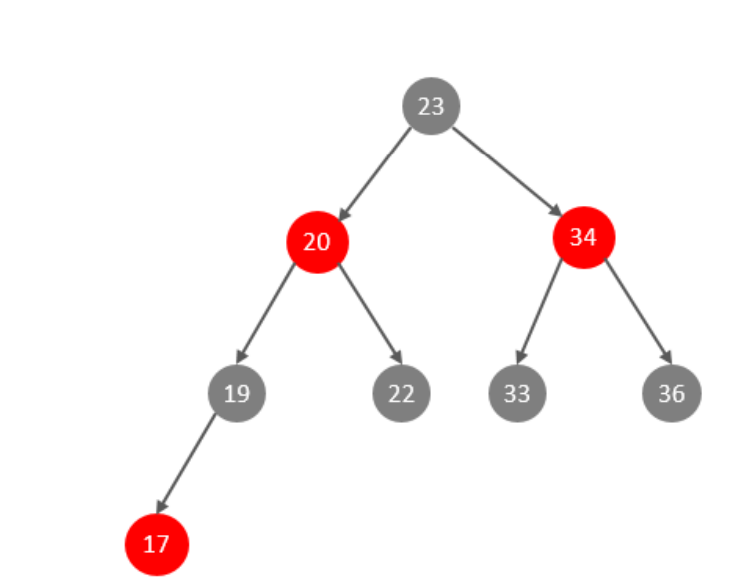
但是,就算是这样,它还是只是个二叉树啊(一个节点一个值,两个指针),它的层级如果数据量大的话还是会很深啊!
所以红黑树仍然存在我们二叉树的第二个问题: 大数据量情况下,层级较深,检索速度慢。
那么你可能会想起来我之前说的一个节点可以存储多个值和指针的数据结构了,如果一个节点存的数据多了,那是不是就可以解决这个问题了。
没错,下面介绍一下B树
B树
B树是个多叉路衡查找树。(名字真绕嘴)
你可以发现名字里面有个多叉,这也是跟二叉树的区别,他有多个叉,也就是说一个节点里面可以存储多个指针。那你可能会问,那一个节点里面存多少值啊,这咋算啊,其实就是指针数-1就是可以存储值的数量。
还有一个注意点: 树的度数指的是一个节点的子节点个数。 (也可以理解是一个节点最多的指针数)
下面是一个5度的B树:
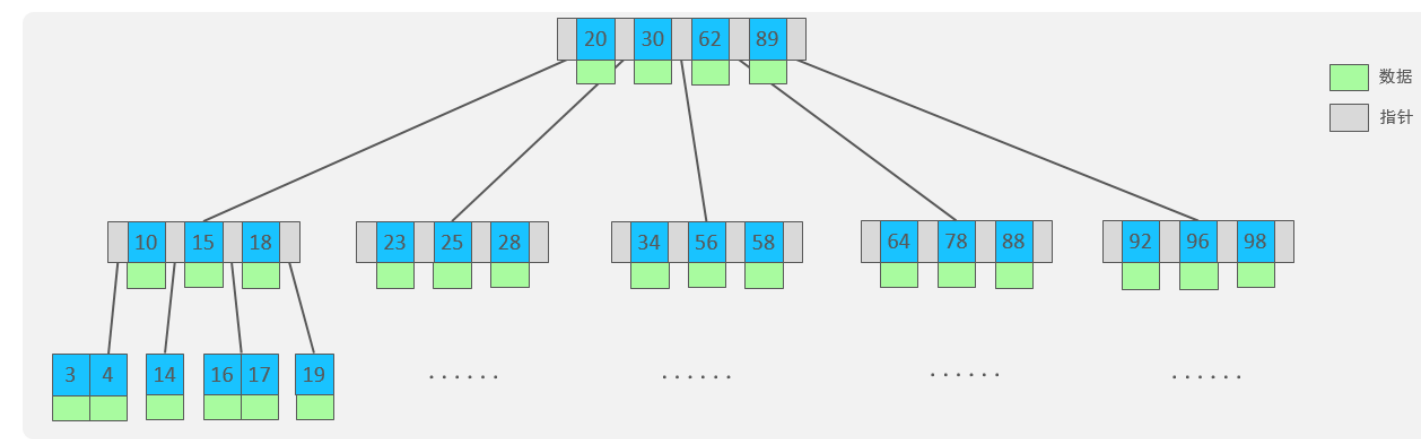
他也跟红黑树一样,是自平衡的(原理是 一旦节点存储的值数量到达5,就会裂变,中间元素向上分裂)
并且你会发现,B树他每个节点中的小节点都是会存储值的,这就是他跟B+树的一个区别。因为有一个知识是:每一个节点都是一个页,一个页的数据量是固定的,如果既存数据,又存指针,那肯定得有更多的节点来存储,有了更多的节点,那是不是层级就更深了。
所以B+树就是只有叶子节点才会存数据,非叶子节点只存储指针和数据的主键
B+树
B+树是B树的一个变种,你会发现B+树跟B树长的真的好像啊。下面是一个B+树的示意图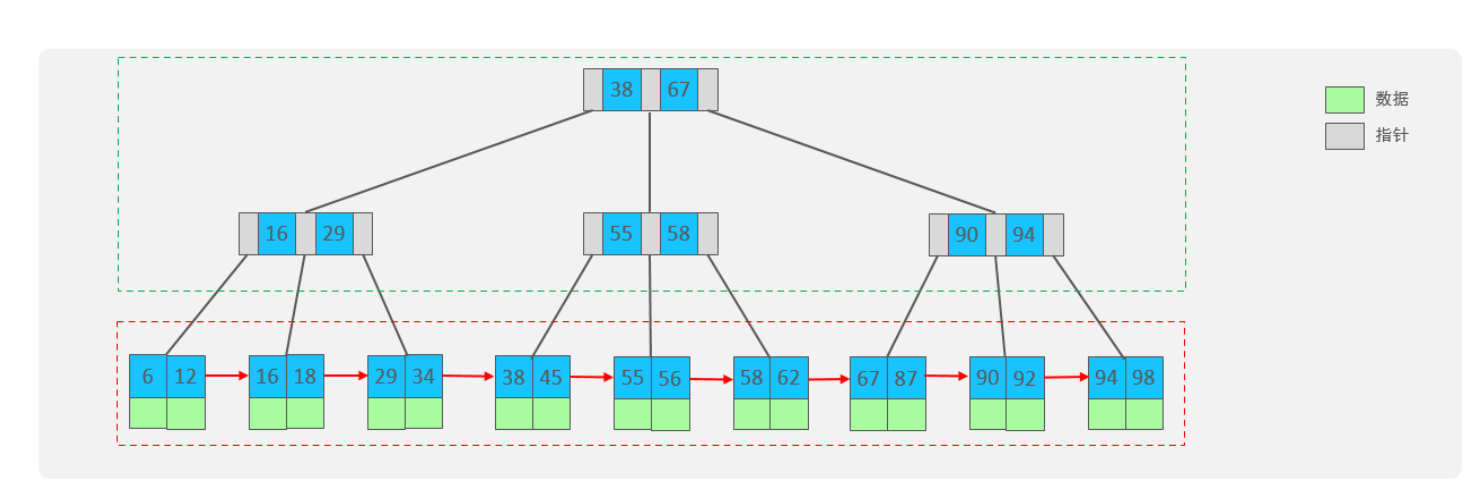
我们可以看到,上面图片被框框分成了两部分:
- 绿色框框起来的部分,是索引部分,仅仅起到索引数据的作用,还保存了数据的一些主键,但是不存储具体数据。
- 红色框框起来的部分,是数据存储部分,在其叶子节点中要存储具体的数据。
最终我们看到,B+Tree 与 B-Tree相比,主要有以下三点区别:
- 所有的数据都会出现在叶子节点。
- 叶子节点形成一个单向链表。
- 非叶子节点仅仅起到索引数据作用,具体的数据都是在叶子节点存放的。
这样的话,是不是解决了层级比较深的问题了呢?
但是我之前提到过,MySql对B+树做了优化
下面就介绍一下
MySQL优化的B+树
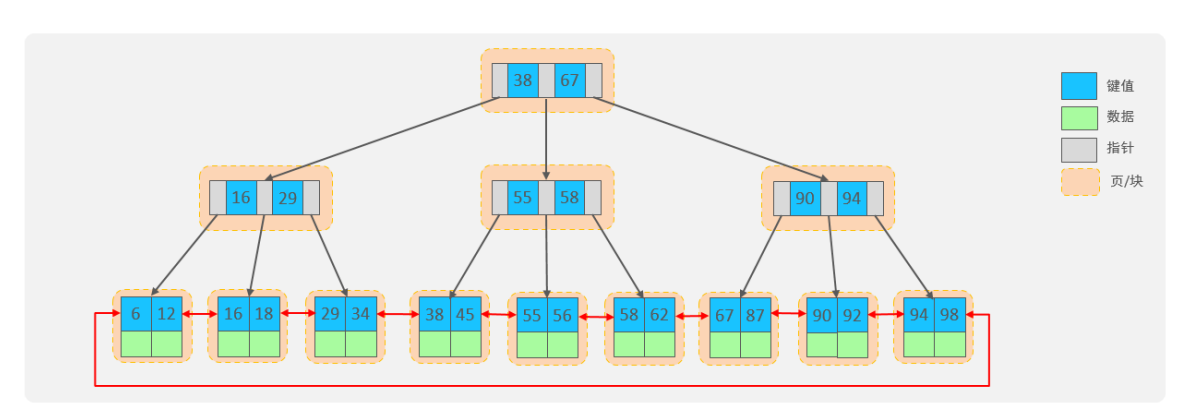
可以看到,底层变成了双向链表,基础版的B+树只是单向链表!
很容易就想到了这样做会有利于区间查询,并且很利于后面往前找。
Hash
你可能会问,为啥要说Hash呢,B+树优化版都那么NB了。
他存在即合理。
MySQL不仅仅支持B+树,还支持Hash索引。
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在 hash表中。
下面就是一个hash表的实例
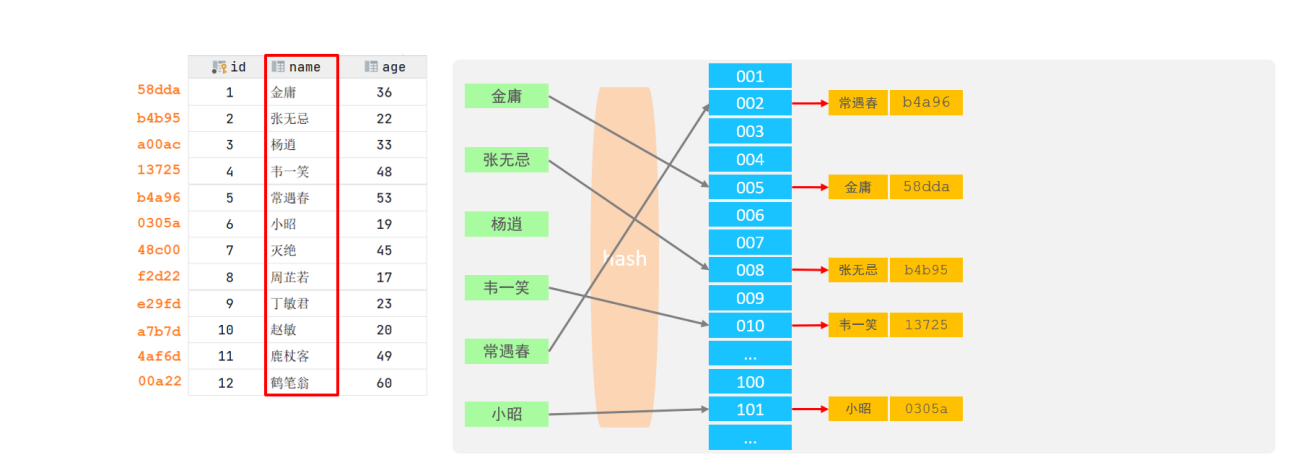
但是只要使用Hash算法,就有hash冲突的可能性,跟Java里面的hashmap一样,可以通过链表来解决
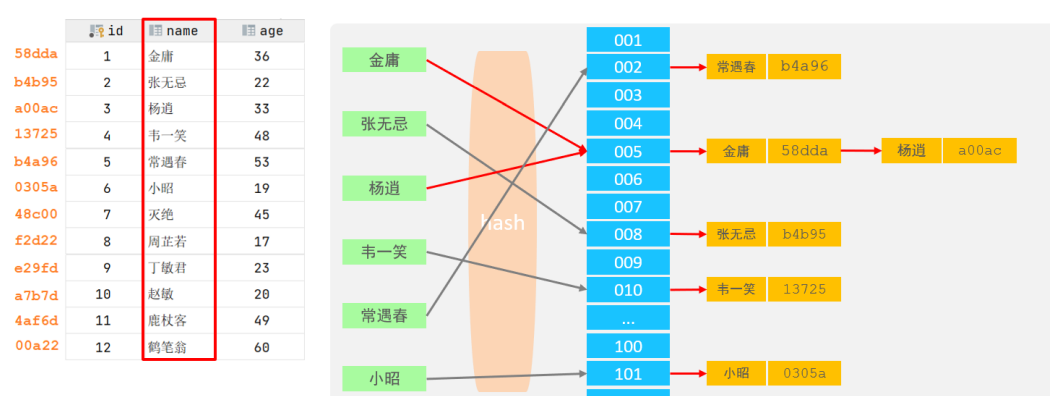
所以为什么要有hash这种算法呢????
因为他查的快啊,直接经过hash运算, 通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
所以可以得出hash数据结构的特点:
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,…)
- 无法利用索引完成排序操作
- 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引
存储引擎支持
在MySQL中,支持hash索引的是Memory存储引擎。
而InnoDB中具有自适应hash功能,hash索引是 InnoDB存储引擎根据B+Tree索引在指定条件下自动构建的。
所以相对于B+树,Hash有好的有坏的,需要根据不同业务场景进行变换